

Natural Language Processing (NLP) refers to the ability of machines to understand and explain the way human write and speak.
It is widely used in information retrieval, sentiment analysis, information extraction, machine translation, and more.
Operations of NLP include:

Tokenization is a process of understanding a sentence or a phrase by splitting them into substrings, words and punctuation.
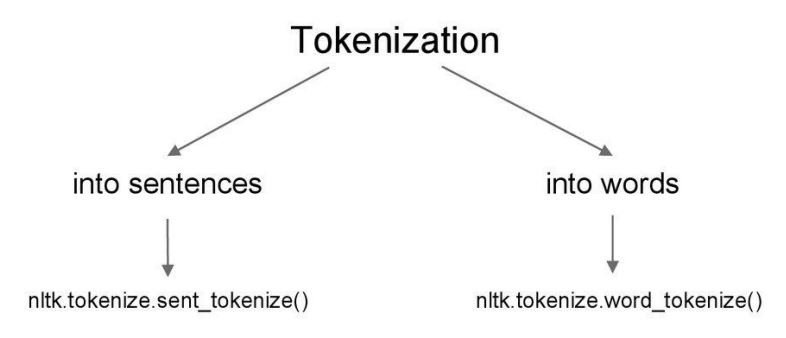
Code Example:
from nltk.tokenize import word_tokenize, sent_tokenize
string = "The science of today is the technology of tomorrow."
# Split the sentence into words
tokenized_words = word_tokenize(string)
print("Word Tokenization: ", tokenized_words)
Output:
['The', 'science', 'of', 'today', 'is', 'the', 'technology', 'of', 'tomorrow', '.']
Stopword Removal involves filtering out words which do not contain significant information. Mostly these are words that are often used as connective tissue such as as, the, be, are etc.

Code Example:
from nltk.corpus import stopwords
string = "The science of today is the technology of tomorrow."
# Load stop words
stop_words = stopwords.words( 'english')
# Remove stop words
nonstop_words = []
for word in tokenized_words:
if word not in stop_words:
nonstop_words.append(word)
print('Nonstop Words: ', nonstop_words)
Output:
['The', 'science', 'today', 'technology', 'tomorrow', '.']
Stemming reduces inflection in words to their root forms by removing the suffixes or prefixes used with a word. As a result, stemming a word or sentence may result in words that are not actual words.

Code Example:
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
string = "The science of today is the technology of tomorrow."
input_words = word_tokenize(string)
# Create stemmer
porter = PorterStemmer()
# Apply stemmer to each word
[porter.stem(word) for word in tokenized_words]
Output:
['the', 'scienc', 'of', 'today', 'is', 'the', 'technolog', 'of', 'tomorrow', '.']
Lemmatization, unlike Stemming, reduces the inflected words properly ensuring that the root word belongs to the language. For example, runs, running, ran are all forms of the word run, therefore run is the lemma (or dictionary form) of all these words.
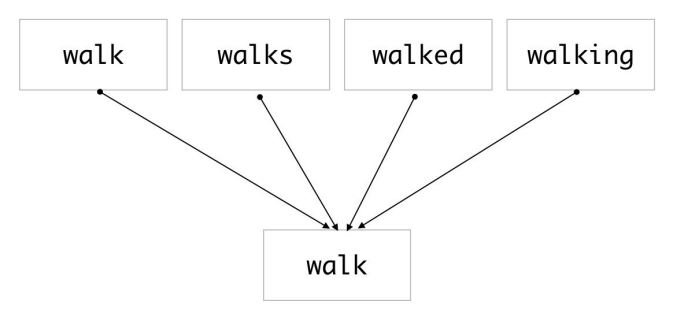
Code Example:
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
string = "The sciences of today are tomorrow's technologies."
input_words = word_tokenize(string)
# Create lemmatizer
lemmatizer = WordNetLemmatizer()
# Apply lemmatizer to each word
[lemmatizer.lemmatize(word) for word in tokenized_words]
Output:
['The', 'science', 'of', 'today', 'is', 'the', 'technology', 'of', omorrow', '.']
Chunking is a set of techniques for entity detection used in text processing, which segments and labels multi-token sequences. For example, noun phrase chunking (NP-chunking) searches for chunks corresponding to individual noun phrases. The process of classifying words into their parts of speech and labeling them accordingly is known as part-of-speech tagging (POS-tagging).

Code Example:
from nltk import pos_tag
from nltk import word_tokenize
string = "The science of today is the technology of tomorrow."
# Apply speech tagging
text_tagged = pos_tag(word_tokenize(string))
print(text_tagged)
Output:
[('The', 'DT'), ('science', 'NN'), ('of', 'IN'), ('today', 'NN'), ('is', 'VBZ'), ('the', 'DT'), ('technology', 'NN'), ('of', 'IN'), ('tomorrow', 'NN'), ('.', '.')]
The Information Retrieval is to extract relevant information from the source.
One of the main goals of text analysis is to convert text into numeric form so that we can use machine learning on it.
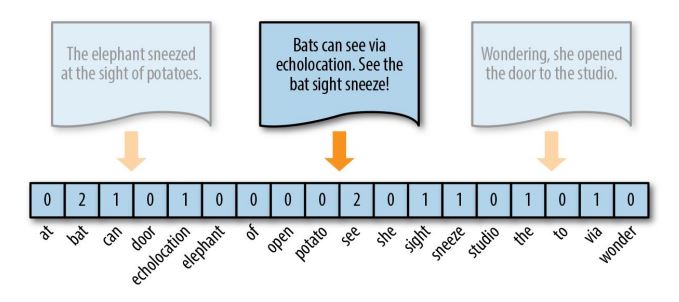
One of primary methods of developing simple language models, is known as the “Bag of Words” (BOW) model, which extracts a vocabulary from all the words in the documents and builds a model using a document term matrix.
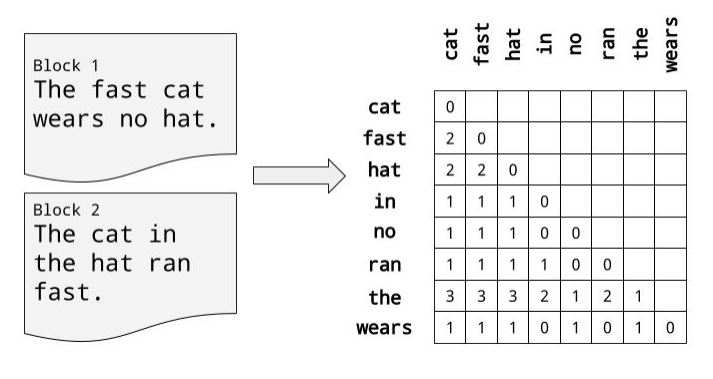
Using BOW approach, every document from a corpus of texts is represented as a vector whose length is equal to the vocabulary of the corpus. The computation is simplified by sorting token positions of the vector into alphabetical order.
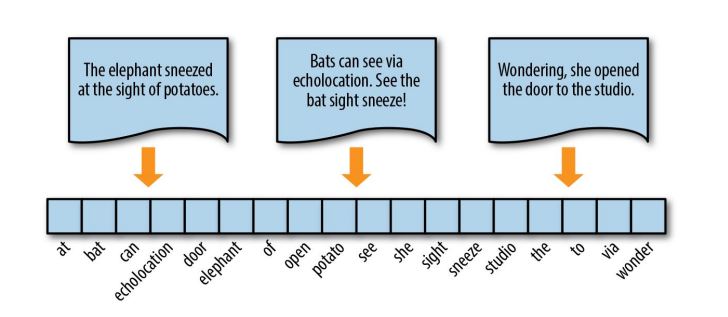
The simplest vector encoding model is to simply fill in the vector with the frequency of each word as it appears in the document.
Code Example:
from nltk import word_tokenize
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
string = "The science of today is the technology of tomorrow."
vectorizer = CountVectorizer()
document_term_matrix= vectorizer.fit_transform(word_tokenize(string))
bag_of_words = np.array(vectorizer.get_feature_names())
print("\nBagOfWords:")
print(bag_of_words)
print("\nDocument term matrix:")
print(document_term_matrix.toarray())
Output:
BagOfWords:
['is' 'of' 'science' 'technology' 'the' 'today' 'tomorrow']
Document term matrix:
[[0 0 0 0 1 0 0]
[0 0 1 0 0 0 0]
[0 1 0 0 0 0 0]
[0 0 0 0 0 1 0]
[1 0 0 0 0 0 0]
[0 0 0 0 1 0 0]
[0 0 0 1 0 0 0]
[0 1 0 0 0 0 0]
[0 0 0 0 0 0 1]
[0 0 0 0 0 0 0]]
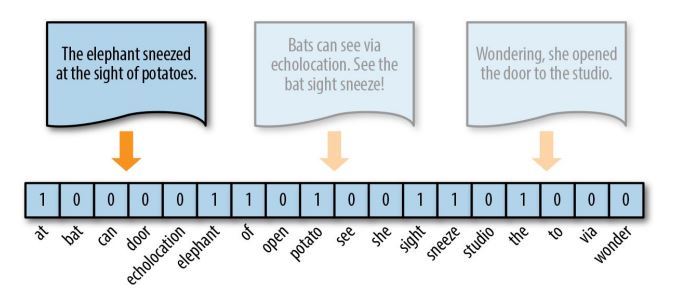
One-hot encoding is another vector encoding method that marks a particular vector index with a value of true (1), if the token exists in the document; with a value of false (0), if it does not exist. This method is effective for very small documents (sentences, tweets) that don’t contain very many repeated elements.
Code Example:
from nltk import word_tokenize
from sklearn.preprocessing import Binarizer
import numpy as np
string = "The science of today is the technology of tomorrow."
tokenized_word = word_tokenize(string)
vectorizer = CountVectorizer()
document_term_matrix = vectorizer.fit_transform(tokenized_word)
onehot = Binarizer()
document_term_matrix = onehot.fit_transform(document_term_matrix.toarray())
bag_of_words = np.array(vectorizer.get_feature_names())
print("\nBagOfWords:")
print(bag_of_words)
print("\nDocument term matrix:")
print(document_term_matrix)
Output:
BagOfWords:
['is' 'of' 'science' 'technology' 'the' 'today' 'tomorrow']
Document term matrix:
[[0 0 0 0 1 0 0]
[0 0 1 0 0 0 0]
[0 1 0 0 0 0 0]
[0 0 0 0 0 1 0]
[1 0 0 0 0 0 0]
[0 0 0 0 1 0 0]
[0 0 0 1 0 0 0]
[0 1 0 0 0 0 0]
[0 0 0 0 0 0 1]
[0 0 0 0 0 0 0]]
Term Frequency-Inverse Document Frequency (TF–IDF) encoding normalizes the frequency of tokens in a document with respect to the rest of the corpus. This encoding approach emphasis terms that have higher relevance to a document.

Code Example:
from nltk import word_tokenize
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
string = "The science of today is the technology of tomorrow."
tokenized_word = word_tokenize(string)
tfidf = TfidfVectorizer()
document_term_matrix = tfidf.fit_transform(tokenized_word)
bag_of_words = np.array(tfidf.get_feature_names())
print("\nBagOfWords:")
print(bag_of_words)
print("\nDocument term matrix:")
print(document_term_matrix.toarray())
Output:
BagOfWords:
['is' 'of' 'science' 'technology' 'the' 'today' 'tomorrow']
Document term matrix:
[[0. 0. 0. 0. 1. 0. 0.]
[0. 0. 1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0.]
[1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0.]]
Word Embeddings represent words in the form of vectors such that similar words are close to each other while antonyms end up far apart in the vector space.
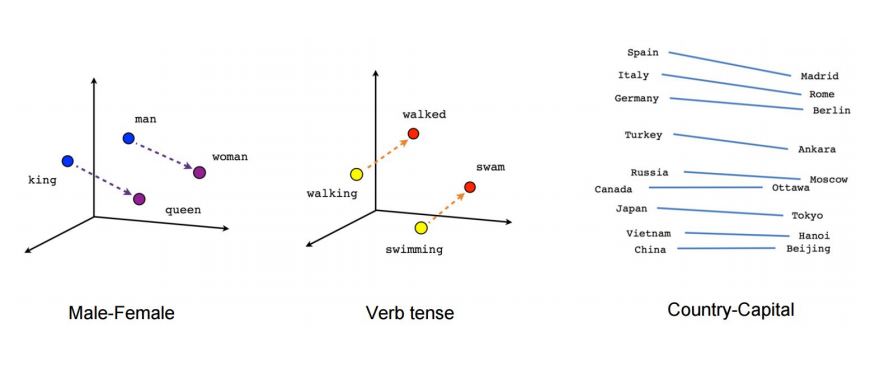
Word2vec by Google is one of several existing models for constructing word-embedding representations, trained to predict a target word from the context of neighboring words. This method is referred to as Continuous Bag Of Words (CBOW).
Going in the other direction, given a set of sentences (corpus) Word2vec analyses the words of each sentence and uses the current word to predict its neighbors, a method called Skip-Gram.

Code Example:
from gensim.models import Word2Vec
sentences = [[ 'data', 'science'],
['science', 'data', 'analytics'],
['machine', 'learning'],
['Woodbury', 'computer', 'science'],
['deep', 'learning']]
# train the model on your corpus
model = Word2Vec(sentences, min_count = 1)
print(model.wv.similarity( 'data', 'science'))
Output:
-0.09619948
End –Cheng Gu