

An artificial neuron is a mathematical function conceived as a model of biological neurons in our brains. Artificial neurons are elementary units in an artificial neural network (ANN). The artificial neuron receives one or more inputs and sums them to produce an output. Usually each input is separately weighted, and the sum is passed through a function known as an activation function.
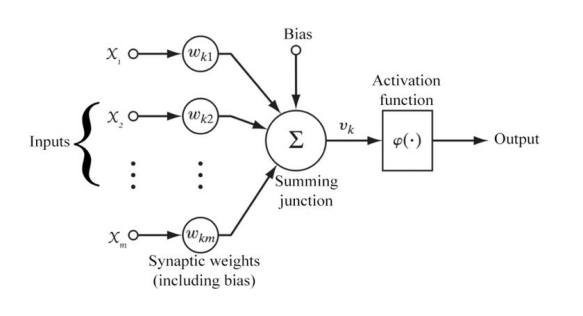
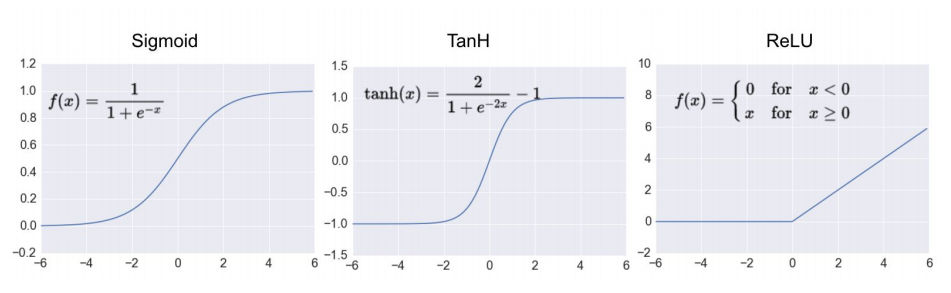
A sigmoid function is a mathematical function having acharacteristic “S” -shaped curve or sigmoid curve and generates outputs between 0 and 1. The sigmoid activation function is widely used in binary classification.
An alternative to the sigmoid is the hyperbolic tangent (Tan-h) function. Like the sigmoid, the tan-h function is also sigmoidal(“S”-shaped), but instead outputs values that range -1 to 1.
Most recent artificial neural networks use rectified linear units (ReLU) for the hidden layers. ReLU has output 0 if the input is less than 0, and raw output otherwise. That is, if the input is greater than 0, the output is equal to the input. (output = max(0, input))
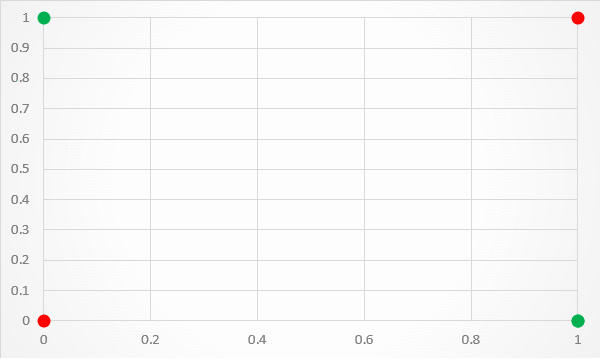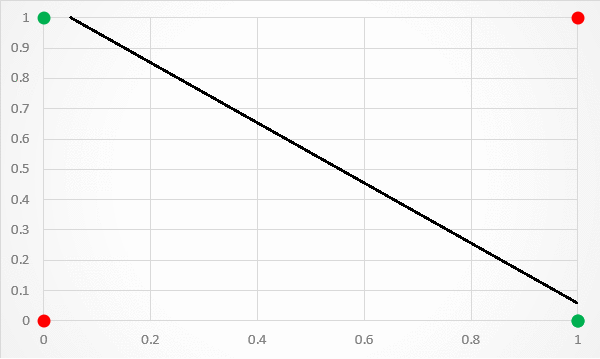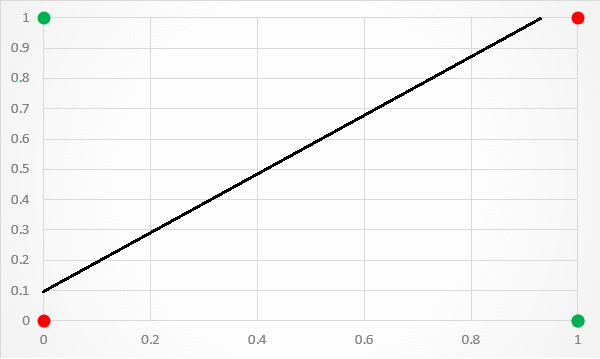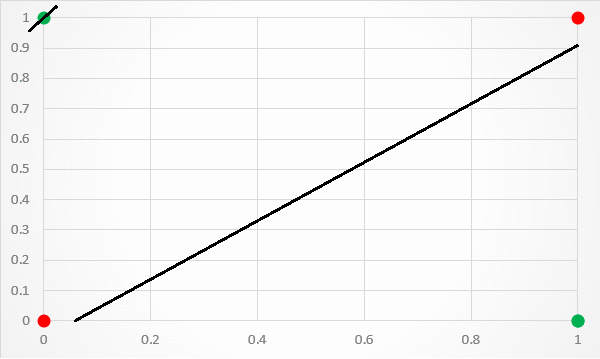
An XOR function should return true if two inputs are not equal ,else return false(Shown as below image):

The XOR problem is a classic problem in ANN Research. It is the problem that there are no ways to using perceptron to predict the True outputs of XOR logic gate given two binary inputs, because XOR inputs are not linearly separable, and perceptron only works for linear separation.
Therefore, duringing that time(1969- 1986), it was “AI Winter” until the MultiLayer Artificial Neural Networks appear(1986).
Artificial Neural Networks(ANNs) are collections of connected nodes made up of artificial neurons(perceptron), providing a framework for different machine learning algorithms to work together and process complex data inputs. Such systems “learn” to perform tasks by considering examples, generally without being programmed with any task-specific rules.
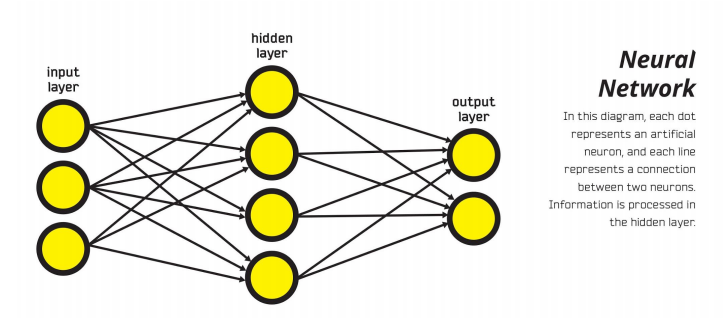
The biggest significance of this architecture is capable of achieving non-linear separation(shown as below):
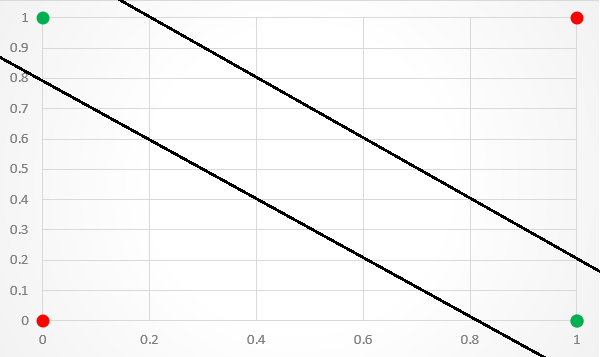
Forward propagation is process of feeding the Neural Network with a set of inputs and comparing the numerical value of the output to the expected output in order to compute the error function.
Back propagation is a method used in ANNs to calculate the weights to be used in the network. It is the backward propagation of errors through the network layers, since an error function is computed at the output. This technique is commonly used to train deep neural networks.

The simplest type of ANN is considered a Feedforward Neural Network, such as perceptron. This means that the information moves only in forward direction from the input nodes, through the hidden nodes to the outputs. A feedforward network has no notion of order in time, and the only input it considers is the current example it has been exposed to.
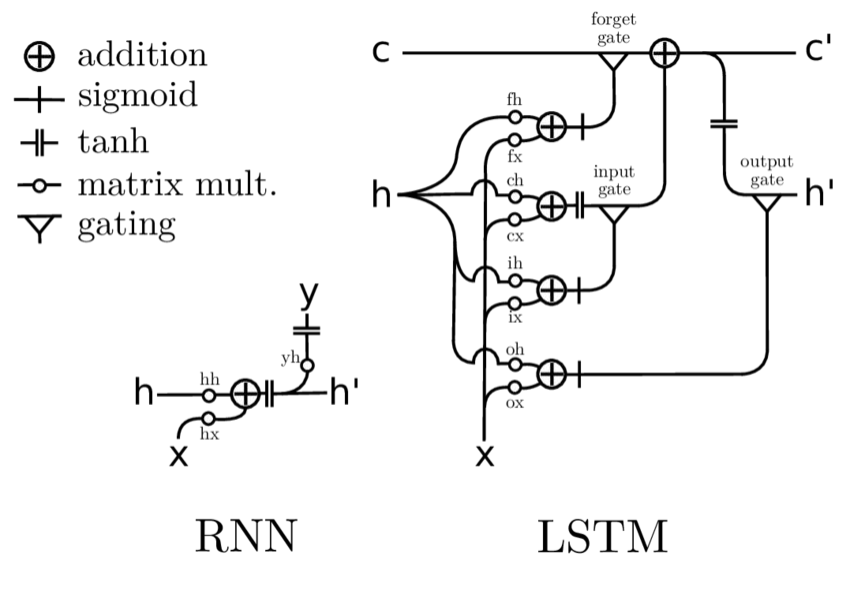
Recurrent Neural Networks (RNNs) are structured in such a way as to take as their input not just the current input example they see, but also what they have perceived previously in time. Recurrent networks are distinguished from feedforward networks by that feedback loop connected to their past decisions. It is often said that recurrent networks have memory

By the early 1990s, the Vanishing Gradient Problem emerged as a major obstacle to RNN performance. Because the information flowing through neural networks passes through many stages of multiplication, the outputs are susceptible to "Vanishing" (gradually decreasing) or "Exploding" (exponentially increasing).
In the mid-90s, a variation of RNN called Long Short-Term Memory (LSTM), was proposed as a solution to the vanishing gradient problem. LSTMs help preserve the error that can be backpropagated through time and layers, allowing RNNs to continue to learn over many time steps (over 1000).
End –Cheng Gu